Una araña en la web (Parte 1) – Diferencia entre Web Crawling y Web Scraping

El año pasado participé del taller DESENVOLVENDO WEB CRAWLERS COM SCRAPY realizado durante la Semana de Computación 2018 (SECOMP 2018) de la UNICAMP. ¿Web Crawler? ¿Scrapy? ¿te animas a saber qué son?
Web crawler (Rastreador web): Es un programa que recoge contenido de la web de forma sistematizada a través del protocolo web estándar (http/https)[1]. Además, en [1] nos dice que hay 3 tareas donde las técnicas de web crawlers son muy utilizadas:
- Motores de búsqueda
- Monitoreo de marcas, noticias, etc.
- Creación de banco de datos para procesamiento de contenido
En [2] nos dicen que cualquier página disponible en internet puede ser visitada e inspeccionada (es decir crawled) y cualquier cosa visible en dicha página puede ser extraída (scraped)
Como cada página posee su propia estructura (Ver figura 1), se tiene que desarrollar un programa específico para extraer la información de dicha estructura.
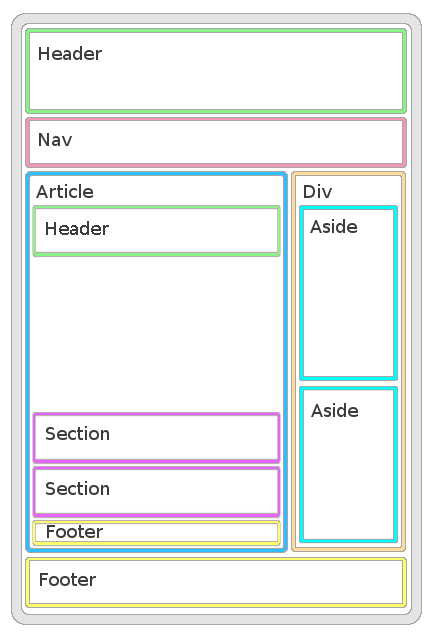
Figura 2: Ejemplo de estructura de una página web (secciones de Header, Nava, Section, Sidebar, Footer entre otros)
Cuando empecé a estudiar este tema de web crawler, me surgió una duda (quizás tú también la tengas en estos momentos):
He escuchado “scrapear” y “crawlear”, pero ¿son procesos iguales? ¿O cuál es la diferencia?.
En [3][4], encontramos lo siguiente:
Web crawling: Es una técnica para visitar todas las páginas de un sitio web o todos los sitios web de un determinado contexto y a medida que va visitando los links de dichas páginas va encontrando más y más links hasta encontrar la información requerida. Es útil para inspeccionar a profundidad un conjunto grande de páginas web, ¿cómo? desarrollando un web crawler (mencionado líneas arriba)
(Web) Scraping: En [4] nos hace hincapié en que el término “scraping” significa en la extracción de información de cualquier fuente (base de datos, archivos csv, etc) y no necesariamente páginas web. Para usar esta técnica es necesario conocer la estructura de la página web de la cual queremos extraer información, es decir deberíamos conocer la estructura HTML de dicha página así como las clases CSS de sus elementos.
Veamos un ejemplo usando la Figura 2 para que quede claro esa diferencia :
Quiero obtener los nombres de los productos que pertenecen a la categoría “laptops” ofrecidos por Amazon.com.
Como 1er paso (Web Crawling), inspeccionaremos/visitaremos todos links del tipo “https://www.amazon.com/s?k=laptop&page=<número de página>“
Como 2do paso (Web Scraping), aplicamos la siguiente “regla” para cada página hallada en el paso anterior: Los nombres de los productos se encuentran en el tag html <span> con clase CSS “product-name” (Ver figura 3). Ejecutamos la regla y comienza la ¡Extracción!, todos los elementos que cumplan dicha regla serán extraídos. Durante este proceso podemos tratar esa información, por ejemplo: convertir todos los nombres a “mayúsculas”.
Ojo: El inspector del navegador web será nuestra herramienta más util para conocer los elementos HTML y el CSS que usa la página de la que queremos extraer información.
Como 3er paso: La información extraída y/o tratada en el paso anterior, debe ser almacenada para posterior análisis (o para lo que deseemos hacer con esa información) en una base de datos, en un archivo csv, excel, json, etc.

Figura 2: Web Crawling y Web Scraping como proceso de tratamiento de información [Creación propia]
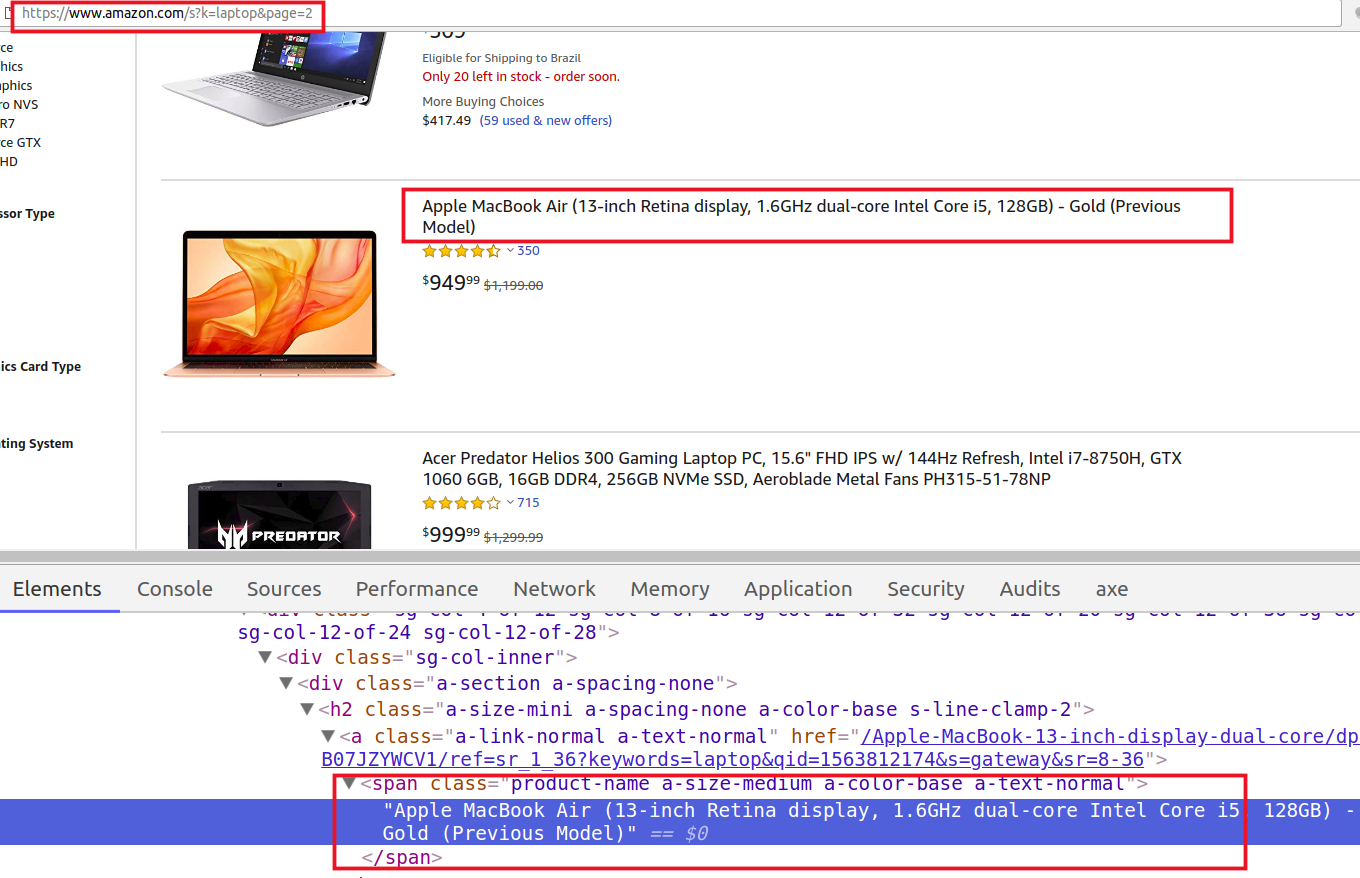 Figura 3 – Ejemplo de elemento html que posee el nombre de un producto (información que queremos extraer)
Figura 3 – Ejemplo de elemento html que posee el nombre de un producto (información que queremos extraer)
Según [3], para poder “scrapear” algunos sitios web, se necesita de ambos procesos: web crawling y web scraping.
¡Listo!
Todo ese proceso explicado líneas arriba, lo podemos realizar con S-C-R-A-P-Y
Scrapy: Es un framework open source para la extracción de información de páginas web. Algunas de las funcionalidades disponibles de Scrapy son controlar la navegación en la web, bibliotecas para analizar HTML, representación de datos y pipelines para filtrar y tratar datos [1]

Figura 3: Arquitectura de Scrapy según [2]
En la siguiente parte veremos cómo crear nuestro 1er spider con Scrapy!. Por mientras les recomiendo este tutorial [5]
Cualquier comentario/duda/corrección, déjame un mensaje en el artículo!

Referencias
[1] Utilizando o Scrapy do Python para monitoramento em sites de notícias (Web Crawler)
[2] Making Web Crawlers Using Scrapy for Python
[3] Web Crawling: Data Scraping vs. Data Crawling
[4] Quora – What are the biggest differences between web crawling and web scraping?
[5] How To Crawl A Web Page with Scrapy and Python 3