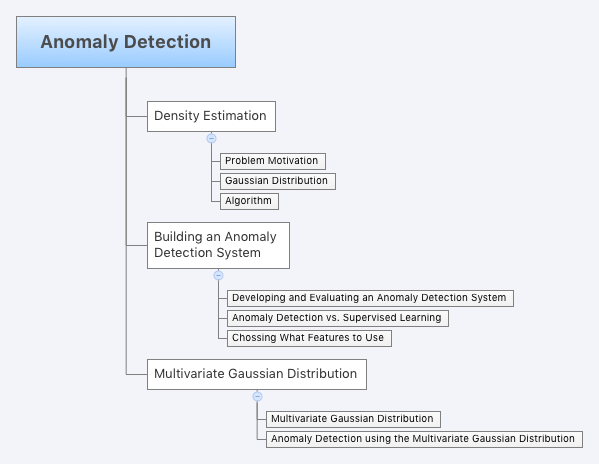
Large Scale Machine Learning
- e.g. Census data, Website traffic data
- Can we train on 1000 examples instead of 100 000 000? Plot
- If high variance, add more examples
If high bias, add extra features
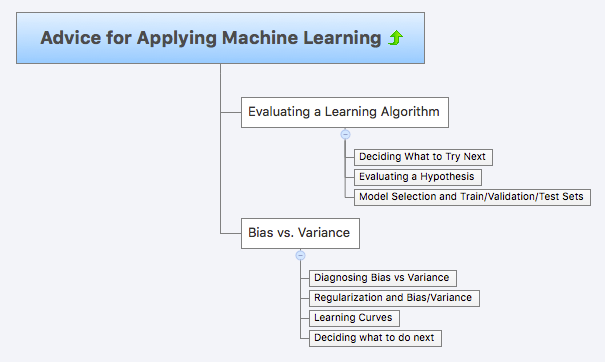
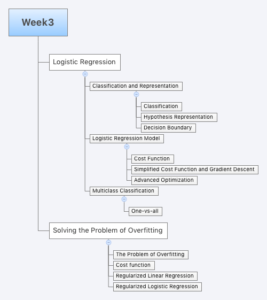
Gradient Descent with Large Datasets
- G.D. = batch gradient descent
- Stochastic Gradient Descent
- cost function = cost of theta wrt a specific example (x^i, y^i). Measures how well the hypothesis works on that example.
- May need to loop over the entire dataset 1-10 times
Mini-Batch Gradient Descent
- Batch gradient descent: Use all m examples in each iteration
- Stochastic gradient descent: Use 1 example in each iteration
- Mini-batch gradient descent: Use b examples in each iteration
- typical range for b = 2-100 (10 maybe)
- Mini-batch Gradient Descent allows vectorized implementation
Can partially parallelize the computation
Advanced Topics
Stochastic G.D. convergence
- every 1000 iterations we can plot the costs averaged over te last 1000 examples
- Learning Rate, smaller learning rate means smaller oscillations (plot)
average over more examples, 5000, may get a smoother curve - If curve is increasing, should use smaller learning rate
- Learning Rate
alpha = const 1 / ( iterationNumer + const2 )
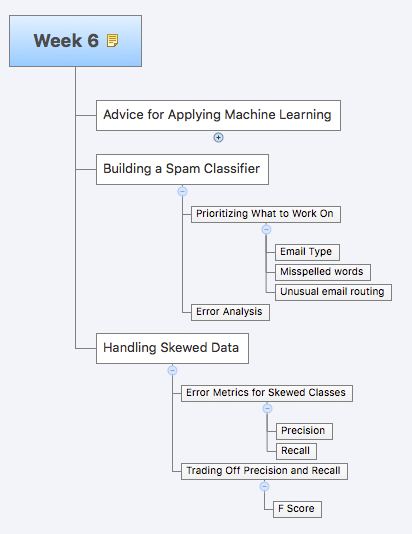
Online Learning
- continuous stream of data
- e.g. 1. shipping service, from origin and destination, optimize the price we offer
- x = feature vector (price, origin, destination)
y = if they chose to use our service or not
- x = feature vector (price, origin, destination)
- e.g. 2. product search
- input: “Android phone 1080p camera”
- we want to offer 10 phones per query
- learning predicted click through rate (CTR)
Map Reduce and Data Parallelism
- Hadoop
- Use local CPU to look at local data
- Massive data parallelism
- Free text, unstructured data
- sentiment analysis
- NoSQL
- MongoDB
Sources