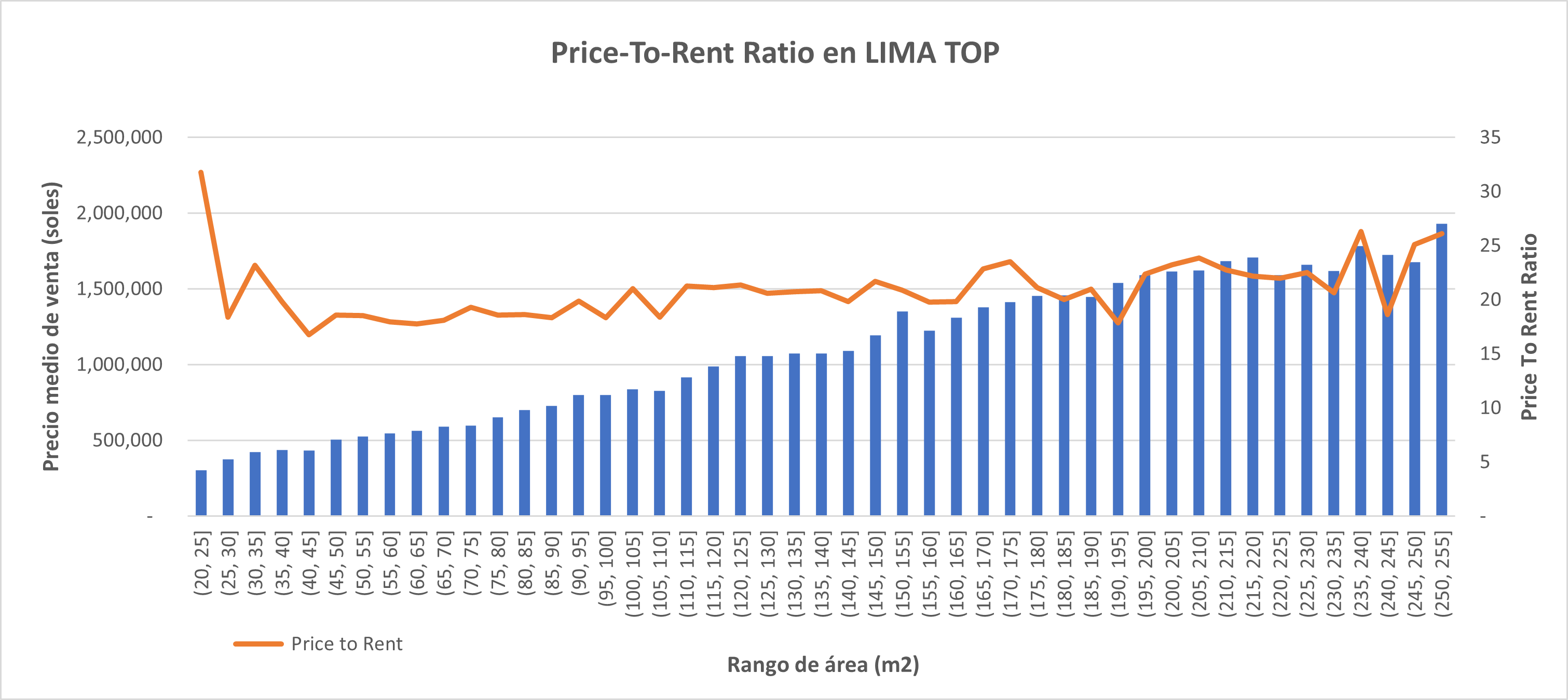
Nadie tiene una bola de cristal para saber con certeza si un prospecto de cliente se convertirá finalmente en nuestro cliente, pero existen herramientas que podrían ayudarnos a estimar, con un sólido nivel de confianza, la probabilidad de compra de un prospecto, el secreto estaría en la información inicial del comportamiento de compra que podemos obtener de este prospecto.
En Machine Learning (ML) existen diferentes herramientas o algoritmos que se pueden definir como cajas blancas en donde ingresamos datos y cada paso del proceso, de una manera clara, transparente e interpretable, es conocida hasta obtener el resultado.
En ciencia, y en particular en la ciencia de datos, se puede ir un paso más allá, con lo que podemos denominar cajas negras donde el ejemplo más específico es el uso de Artificial Neural Networks (ANN). Esto quiere decir que nosotros conocemos los datos o inputs que entregamos al modelo y entendemos el output o resultado que obtenemos, pero no tenemos un claro entendimiento de lo que pasa dentro del proceso del algoritmo por la complejidad de las interrelaciones que suceden al interior del algoritmo.
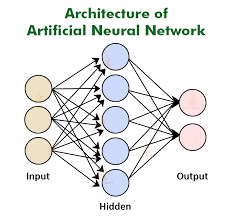
Imagen. https://www.cybiant.com/resources/artificial-neural-networks/
Muchas empresas grandes usan este tipo de algoritmos y confían en los resultados debido a la enorme cantidad de datos que poseen
¿Como podemos usar nosotros estos algoritmos y sacar provecho como lo hacen empresas grandes? Pues en un mundo digital donde el primer contacto de nuestros compradores es también digital nosotros podemos capturar el comportamiento de navegación de usuarios de nuestras plataformas donde mostramos nuestros proyectos. Muchas otras industrias, sobre todo la de e-commerce, usan este tipo de información de los usuarios para poder predecir el comportamiento de compra, recompra, churn, y más de sus usuarios.
Para aterrizar lo comentado voy a mostrar un proceso de análisis de probabilidad de recompra de clientes existentes de una tienda online de audiolibros.
En los datos que tenemos al menos un cliente ha comprado, en anterior oportunidad, un audiolibro. La idea principal es que la compañía no debería gastar esfuerzos, ni dinero en usuarios que no están dispuestos a comprar de nuevo. Si nos enfocamos en aquellos usuarios que están dispuestos a hacer recompras vamos a obtener mayores ventas y mayor rentabilidad.
El modelo de Deep Learning tomara diferentes métricas y tratara de predecir el comportamiento de compra. También vamos a poder identificar las mejores métricas que nos muestren que un cliente comprara de nuevo.
A continuación, muestro un ejemplo de la data que tenemos para analizar.
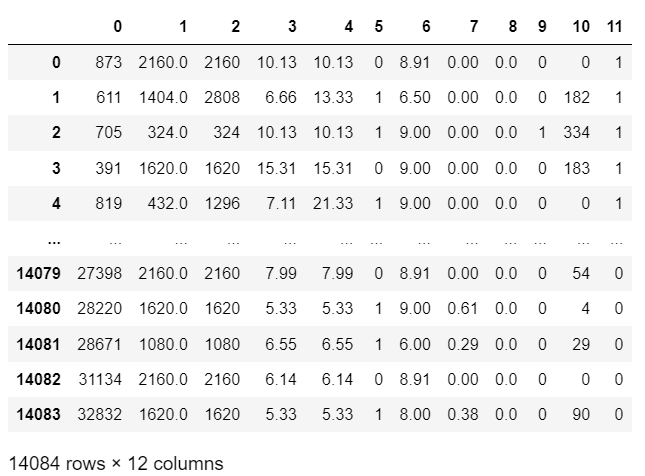
En cada fila tenemos un cliente. En las columnas tenemos el ID del usuario, tenemos la duración del audiolibro, precio del audiolibro, precio promedio que incluye compras anteriores, si dejó un review, escala del review que dejó, minutos escuchados del audiolibro, ratio de conclusión del audiolibro, requerimiento de soporte, última visita a la plataforma y la columna objetivo de recompra.
Una vez procesada la data: balanceada, dividida en train and test data y guardada en un formato amigable para TENSORFLOW, procedimos a crear el algoritmo de Machine Learning.
Construcción de nuestra Neural Network
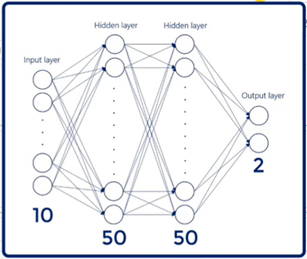
- Inputs Layer size (predictors): 10
- Hidden Layer: 2 de 50 c/u
- Output Layer size: 2
- Batch_size = 100
- Max_epochs = 100
- Early_stopping = tf.keras.callbacks.EarlyStopping

Imagen. https://www.adictosaltrabajo.com/2020/11/26/instalacion-de-tensorflow-y-entorno-de-desarrollo-python-en-mac/
Una vez corrido el algoritmo de entrenamiento obtuvimos un validation_accuracy: 0.9172, es decir que podríamos predecir la recompra de un cliente en un 92% de los casos con nuestro modelo.
Ahora vamos a testear nuestro modelo con data que nuestro algoritmo no ha visto jamás, es decir, con datos de testeo de prospectos de clientes.
En esta corrida del algoritmo nuestro modelo obtiene un test_accuracy: 0.9152, este valor es un poco menor al que obtuvimos en el proceso de entrenamiento lo cual teóricamente sería correcto. Este valor
nos indica que podríamos hacer una predicción solida sobre la probabilidad de recompra de 9 de 10 usuarios. Podemos usar esta información para enfocar nuestros esfuerzos de marketing y ventas en aquellos usuarios que tienen mayor probabilidad de compra.
Ahora hagamos las predicciones con nueva data. Para esto cargamos la data en una nueva variable, la procesamos, la escalamos y usamos el modelo que guardamos anteriormente.

Obtuvimos dos columnas, la columna de la izquierda nos indica la probabilidad de clasificación como 0 y la columna de la derecha nos indica la probabilidad de clasificación como 1, donde 0 es no compra y 1 es compra.
Conclusión
Como podemos ver obtuvimos la probabilidad de compra de nuevos usuarios. Con estos resultados podemos optimizar nuestros esfuerzos de marketing y ventas para poder centrarnos en aquellos prospectos que tendrían mayor probabilidad de compra. Este proceso es iterativo y se va optimizando a lo largo del proceso de ventas.
Hemos podido demostrar que herramientas como ANN pueden ser muy útiles para optimizar nuestros procesos de marketing y ventas.
Este mismo proceso se lleva a cabo en diferentes industrias y en la industria inmobiliaria no debería ser diferente.