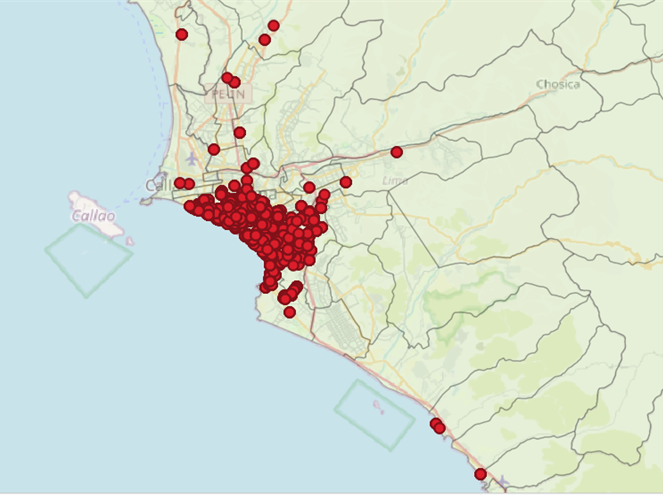
La segmentación de clientes es importante para que las empresas comprendan a su público objetivo. Se pueden seleccionar y enviar diferentes anuncios a diferentes segmentos de audiencia según el perfil demográfico, intereses, nivel socio económico, etc.
Diferentes industrias como las de e-commerce, financiera, retail aprovechan esto para optimizar los recursos en marketing y dirigir el speech adecuado a su segmento objetivo.
Hay varios algoritmos de aprendizaje automático no supervisados que pueden ayudar a las empresas inmobiliarias a identificar su base de clientes y segmentarlos.
Nosotros usaremos una técnica popular de aprendizaje no supervisado llamada K-Means.
El objetivo de K-Means es agrupar todos los datos disponibles en subgrupos que no se superponen y que son distintos entre sí.
Eso significa que cada subgrupo o clúster constará de características que los distinguen de otros subgrupos o clústeres.
Proceso de segmentación
Primero cargamos los datos a analizar.
Luego, para poder encontrar el género de cada cliente se usó una librería conocida como NLTK. Usando los nombres de cada cliente se pudo identificar el género de todos los clientes.
Para anonimizar el análisis se borraron las columnas del Nombre y DNI de los clientes, además, que no aporta ninguna información útil sobre el clúster.

Dado que el MEDIO, ESTADO CIVIL, TIPO DE VENTA y GENERO son variables categóricas, debe codificarse para convertirse en numérico, en este caso usamos pd.get_dummies() para crear variables numéricas.
Por otro lado, necesitamos estandarizar las variables numéricas en el conjunto de datos para que estén en la misma escala.
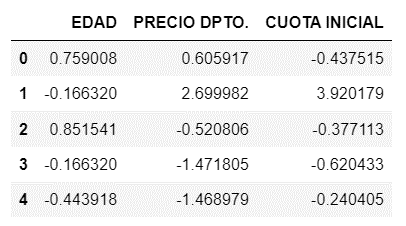
Al final los datos quedarían de esta forma para poder usar el método K-Means.
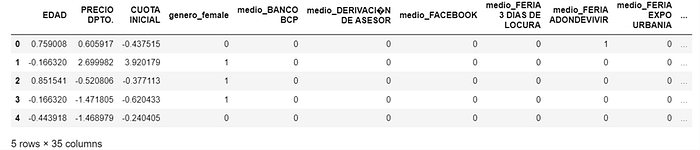
Podemos observar que las variables categóricas se han transformado en variables numéricas. Además, hemos eliminado la variable “genero_male” debido a que ya no es necesario mantener la variable.
Construyendo las segmentaciones

Visualización del rendimiento del modelo:
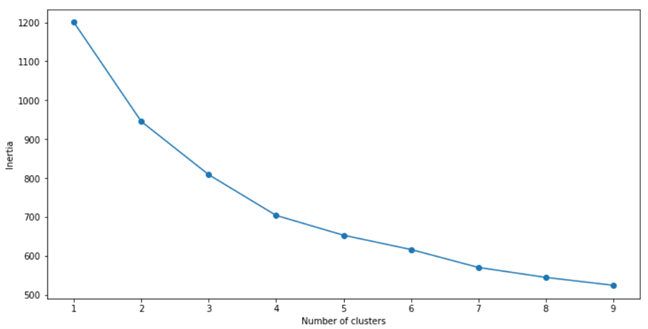
Podemos ver que el numero óptimo de clústeres es 4.
Veamos otra métrica para la segmentación (Silhouette coefficient).
Este coeficiente de silueta es utilizado para evaluar la calidad de los grupos creados por el algoritmo.
Los valores del coeficiente oscilan entre -1 y +1. Cuanto mayor sea la puntuación de la silueta, mejor será el modelo.
Calculemos el valor del coeficiente de silueta del modelo que acabamos de construir:

El valor del coeficiente de silueta de este modelo es aproximadamente 0.23.
Este no es un mal modelo, pero podemos hacerlo mejor e intentar obtener una mayor separación de grupos.
Construiremos el segundo modelo de agrupamiento.
Para el segundo modelo vamos a seleccionar las variables principales del modelo.
Podemos utilizar una técnica llamada Análisis de Componentes Principales (PCA).
PCA es una técnica que nos ayuda a reducir la dimensión de un conjunto de datos. Cuando ejecutamos PCA en un marco de datos, se crean nuevos componentes. Estos componentes explican la varianza máxima del modelo.

El código anterior generá el siguiente gráfico:

Este gráfico nos muestra los 4 primeros componentes de PCA, junto con su variación.
Según esta visualización, podemos ver que los 4 primeros componentes de PCA explican alrededor del 70% de la varianza del conjunto de datos.
Ahora podemos introducir estos 4 componentes en el modelo.
Construyamos el modelo nuevamente con los dos primeros componentes principales y decidamos la cantidad de clústeres que se usarán:

El código anterior generara el siguiente gráfico:

De nuevo, parece que el numero óptimo de clústeres es 4.
Podemos calcular el valor del coeficiente de silueta para este nuevo modelo con 4 grupos.

El valor del coeficiente de silueta de este modelo es aproximadamente 0.35, que es mejor que el modelo anterior que creamos.
Análisis de segmentación
Ahora que hemos terminado de construir estos diferentes grupos, intentemos interpretarlos y observemos los diferentes segmentos de clientes.
Para comparar los atributos de los diferentes grupos, busquemos el promedio de todas las variables en cada grupo.
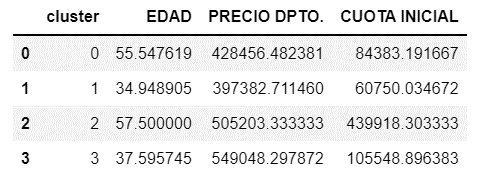
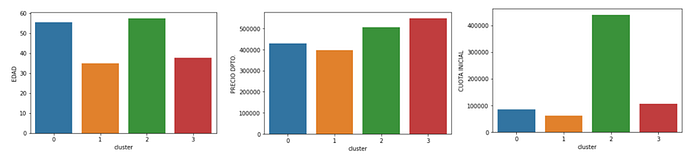
Podemos Interpretar estos grupos más fácilmente si los visualizamos.
Desglose por cantidad de clientes en cada clúster:

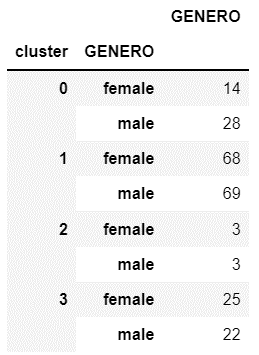
Desglose por género:
Atributos principales de cada clúster o segmento de clientes
Grupo 0:
· Edad promedio 55 años.
· Precio promedio de compra alrededor de 430,000 soles.
· Cuota inicial que entrega alrededor de 84,000 soles.
· Representa el 18% del total de clientes.
· El género es predominantemente masculino.
· Los 3 medios principales por los que llegaron al proyecto fueron: WEB de Inmobiliaria (21%), por la construcción (19%) y referidos de otros Propietarios (14%).
· Los dos tipos principales de financiamiento que usaron fueron: Hipotecario (63%) y Ahorro Mivivienda (26%).
Grupo 1:
· Edad promedio 35 años.
· Precio promedio de compra alrededor de 400,000 soles.
· Cuota inicial que entrega alrededor de 60,000 soles.
· Representa el 59% del total de clientes.
· Ambos géneros tienen la misma representatividad en este grupo.
· Los 3 medios principales por los que llegaron al proyecto fueron: WEB de Inmobiliaria (23%), referidos de otros Propietarios (15%), portal Nexo Inmobiliario (9%).
· Los dos tipos principales de financiamiento que usaron fueron: Ahorro Mivivienda (85%) e Hipotecario (9%).
Grupo 2:
· Edad promedio 57 años.
· Precio promedio de compra alrededor de 500,000 soles.
· Cuota inicial que entrega alrededor de 440,000 soles.
· Representa el 3% del total de clientes.
· Ambos géneros tienen la misma representatividad en este grupo.
· El medio principal por el que llegaron al proyecto fue: referidos de otros Propietarios (67%).
· Los dos tipos principales de financiamiento que usaron fueron: Contado (50%) y Crédito directo (33%).
Grupo 3:
· Edad promedio 37 años.
· Precio promedio de compra alrededor de 550,000 soles.
· Cuota inicial que entrega alrededor de 100,000 soles.
· Representa el 19% del total de clientes.
· Ambos géneros tienen la misma representatividad en este grupo.
· Los 3 medios principales por los que llegaron al proyecto fueron: WEB de Inmobiliaria (23%), por la construcción (19%) y referidos de otros Propietarios (19%).
· Los dos tipos principales de financiamiento que usaron fueron: Hipotecario (79%) y Ahorro Mivivienda (13%).
Conclusiones
Logramos construir con éxito un modelo de clustering de K-Means para la segmentación de clientes de un proyecto inmobiliario. También exploramos la interpretación de grupos y analizamos el comportamiento de los individuos en cada segmento, grupo o clúster.
Un siguiente paso, una vez conocidos los atributos de cada grupo, es crear CUSTOMER PERSONAS a su alrededor, para luego generar recomendaciones comerciales según los atributos vistos de cada grupo para futuros clientes a los que van dirigidos los proyectos.